Lenses
CVPR 2026
Lenses: Toward Polysemous
Vision-Language Understanding
Virginia Tech
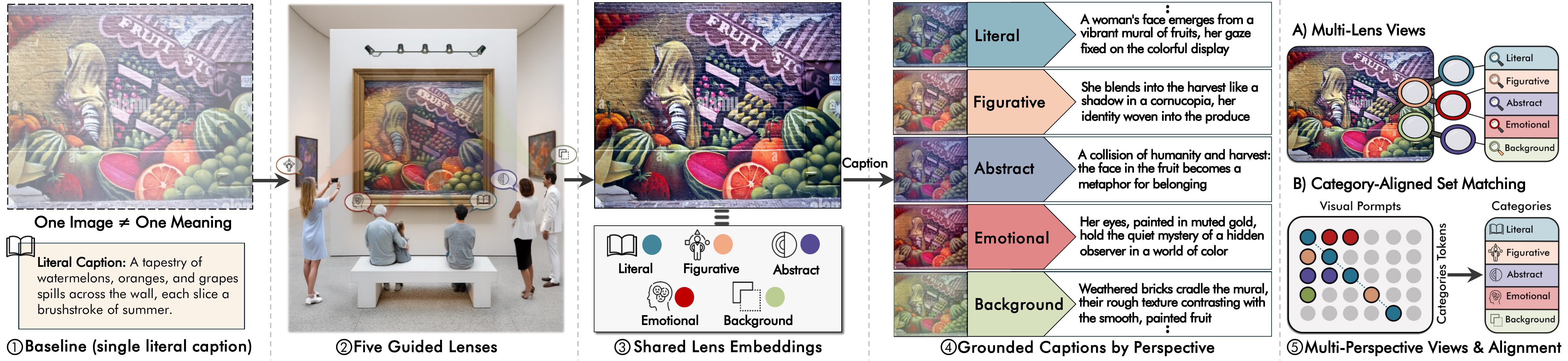
Abstract
Most vision-language models assume images have a single literal meaning, even though images are polysemous. We propose a retrieval paradigm that models many-to-many relationships between images and text using interpretive lenses and introduce Lenses, a multi-prompt embedding model and dataset for polysemous image-text retrieval. The Lenses dataset contains 105,669 images and 732,405 captions, with each image paired with multiple captions and image-side prompts annotated across five categories: Literal, Figurative, Emotional, Abstract, and Background. Building on a multimodal large language model, the Lenses model uses learned lens tokens to extract lens-specific embeddings for every image and caption and compares these using a lens-masking similarity function with a global fallback that prioritizes same-lens matches while retaining a global pathway. Training uses a category-aware multi-positive contrastive loss and intra-set diversity regularization to align corresponding perspectives while preventing semantic collapse across lenses. We further propose lens-aware evaluation protocols, including category-aware ranking, that better reflect how humans match images and text. Experiments on the Lenses dataset and public benchmarks show that our model outperforms baselines on literal and non-literal retrieval and reduces over-reliance on literal cues.
Five Interpretive Lenses
The same image can mean different things to different people. Lenses captures this through five distinct perspectives:
Literal
What you directly see in the image
Figurative
Metaphors, idioms, and symbolic readings
Emotional
Feelings and moods evoked by the scene
Abstract
Conceptual themes and deeper ideas
Background
Historical or cultural context
Key Contributions
- Lenses Dataset — 105K images with 732K captions across five interpretive lenses, sourced from CC3M and WikiArt, with multi-stage validation.
- Multi-Prompt Embedding Model — Special lens tokens extract distinct, prompt-conditioned embeddings from a single MLLM forward pass, producing heterogeneous slot representations.
- Lens-Masking Similarity — A category-aware matching function that only allows same-lens slots to interact, with a global embedding fallback for robustness.
- Category-Aware Training — Multi-positive contrastive loss with lens-conditioned caption-prompt alignment and intra-image diversity regularization to prevent slot collapse.
- Lens-Aware Evaluation — New protocols including per-lens retrieval and lens-coverage metrics that reveal performance differences invisible to standard Recall@K.
Dataset at a Glance
105K
Images
732K
Captions
5
Interpretive Lenses
~7
Captions / Image
Results
Image-to-Text Recall@1 on the Lenses test set across interpretive lenses:
| Model | Literal | Figurative | Emotional | Abstract | Background | Overall |
|---|---|---|---|---|---|---|
| BGE-VL (zero-shot) | 63.3 | 28.2 | 14.8 | 17.4 | 7.9 | 70.7 |
| BGE-VL (fine-tuned) | 67.3 | 47.5 | 33.8 | 33.5 | 24.9 | 80.9 |
| Lenses (Ours) | 80.3 | 56.0 | 40.4 | 41.3 | 34.0 | 89.1 |
Lenses roughly doubles Figurative R@1 and improves Background R@1 by +26 points over the zero-shot baseline.
BibTeX
@inproceedings{alomari2026lenses,
title = {Lenses: Toward Polysemous Vision-Language Understanding},
author = {Alomari, Hani and Asgarov, Ali and Thomas, Chris},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR)},
year = {2026}
}