
Hi, I’m Hani Alomari 👋
Ph.D. student in Computer Science at Virginia Tech, working with Dr. Chris Thomas on multimodal learning and vision-language representations, with an emphasis on building retrieval systems that capture diverse, non-literal meaning across images, text, video, and audio.
Research Interests
✨ Vision-Language Models 🔄 Cross-Modal Retrieval 🧠 Multimodal Reasoning
Recent News
Feb '26 Lenses accepted to CVPR 2026
Jan '26 3 papers under review at ACL Rolling Review
May '25 MaxMatch accepted to ACL 2025
Selected Publications

Hani Alomari, Ali Asgarov, Chris Thomas
CVPR 2026 Project Page
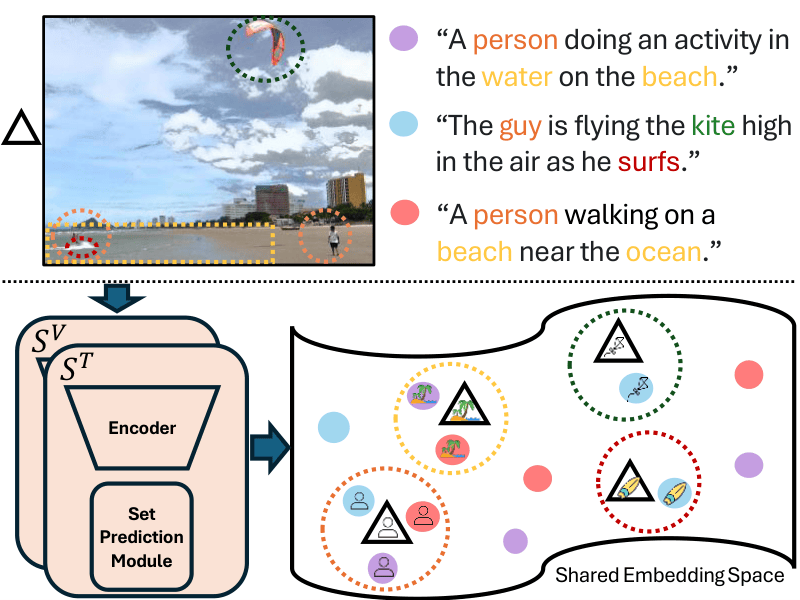
Maximal Matching Matters: Preventing Representation Collapse for Robust Cross-Modal Retrieval
Hani Alomari, Anushka Sivakumar, Andrew Zhang, Chris Thomas
ACL 2025 Paper
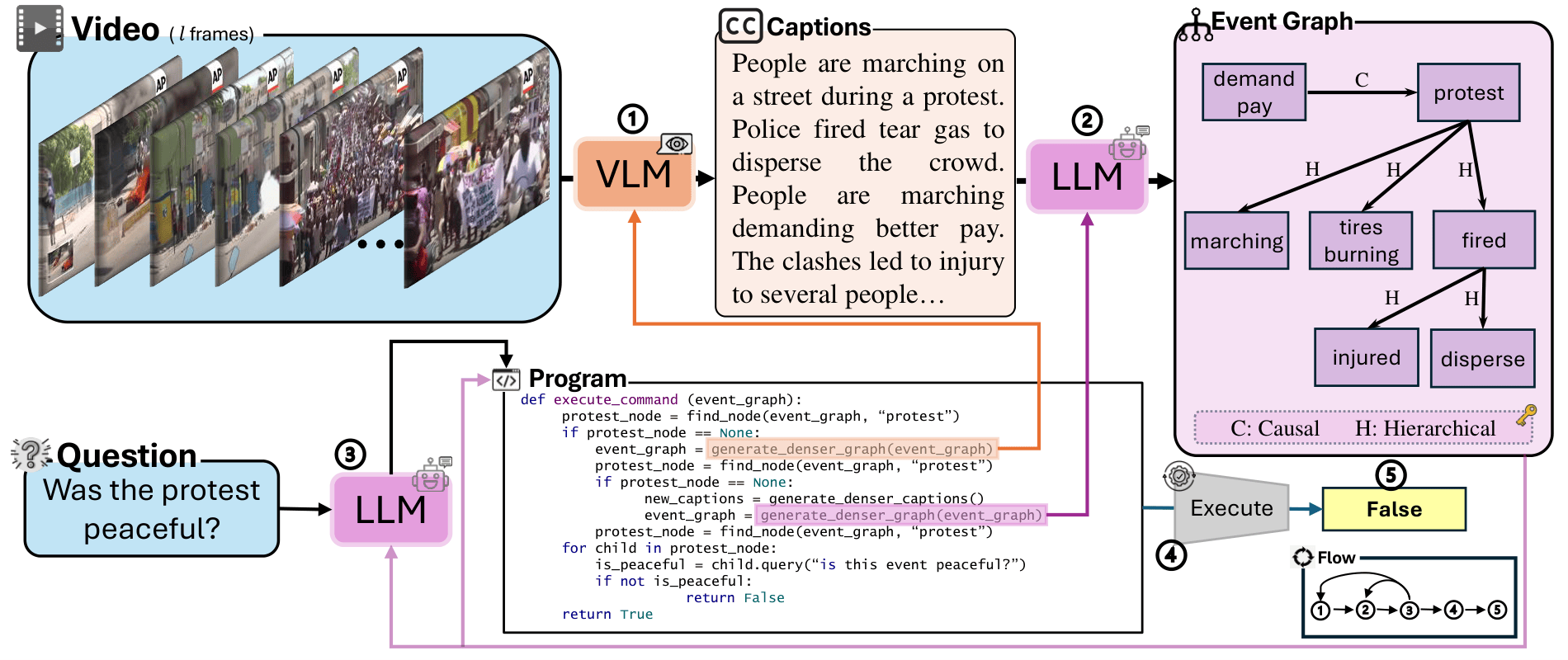
ENTER: Event-Based Interpretable Reasoning for VideoQA
Hammad Ayyubi, Junzhang Liu, Ali Asgarov, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, Zhecan Wang, Chia-Wei Tang, Hani Alomari, et al.
NeurIPS 2024 MAR Workshop · Spotlight
Paper See publications page for the complete list and links.